
Many companies provide a Disaster Recovery environment to ensure continued operation during natural disasters, political strife, epidemics or other potential disruptions to business. The IT Disaster Recovery Plan is typically part of a wider Business Continuity Programme, and it can be a major expense for any company.
Expenses involved in providing a Disaster Recovery capability can often approach (or even exceed, due to data replication requirements) the cost of the primary IT Production costs, which leads some comapnies to try to save money by reducing the capabilities in the Disaster Recovery environment.
The good news is that Amazon Web Services (AWS) can be used as part of a strategic IT Disaster Recovery Plan and will usually be lower in cost than existing capabilities, and most likely provide a better time to recovery. We outline 4 different strategies here that can form the basis of an effecient and cost-effective Disaster Recovery plan:
The actual strategies used depends on RTO/RPO requirements and budgets, and will be different for every company
A traditional approach to DR involves different levels of off–site duplication of data and infrastructure. Critical business services are set up and maintained on this infrastructure and tested at regular intervals. The disaster recovery environment‘s location and the Production infrastructure should be a significant physical distance apart to ensure that the disaster recovery environment is isolated from faults that could impact the Production site. This requirement may be mandated by regulatory authorities
At a minimum, the infrastructure that is required to support the Diaster Recovery environment should include the following:
Recovery Time Objective (RTO) : The time it takes after a disruption to restore a business process to its service level, as defined by the operational level agreement (OLA). For example, if a disaster occurs at 12:00 PM (noon) and the RTO is eight hours, the DR process should restore the business process to the acceptable service level by 8:00 PM.
Recovery Point Objective (RPO) : The acceptable amount of data loss measured in time. For example, if a disaster occurs at 12:00 PM (noon) and the RPO is one hour, the system should recover all data that was in the system before 11:00 AM. Data loss will span only one hour, between 11:00 AM and 12:00 PM (noon).
A company typically decides on an acceptable RTO and RPO based on the financial impact to the business when systems are unavailable. The company determines financial impact by considering many factors, such as the loss of business and damage to its reputation due to downtime and the lack of systems availability.
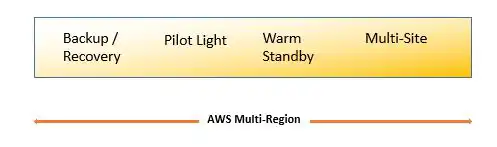
IT organizations then implement solutions to provide cost–effective system recovery based on the RTO/RPO requirements of the firm.
The approach taken, whether backup/restore, pilot light, warm standby or multisite operation depends on RTO/RPO requirements and available budget
The cost of providing Disaster Recovery is typically a significant expense to the business, particularly when stringent RTO/RPO are required. Companies sometimes compromise their Disaster Recovery environment in order to save cost. Using an AWS Disaster Recovery strategy may allow you to meet requirements and stay within budget!
